

Part 2: MetroCluster in ONTAP 8.3
In my previous blog, I talked about how Advanced Disk Partitioning (ADP) is going to be a big benefit to nearly all of NetApp’s customer base. This installment is all about another exciting announcement from Insight that may not be getting much press—MetroCluster functionality in ONTAP 8.3.
While previously only available in 7-Mode, ONTAP 8.3 officially brings MetroCluster to clustered architectures. ONTAP 8.3 also brings quite a few exciting updates to MetroCluster that are sure to expand adoption and improve the overall customer experience.
What’s New in MetroCluster 8.3?
More shelves: Cleaner install, higher cost
MetroCluster is a feature that has been around for a while as part of Data ONTAP 7-Mode. MetroCluster is a combination of array-based clustering and synchronous mirroring between a primary and secondary data site. By continuously replicating data across a customer’s data real-estate, MetroCluster provides rapid and seamless recovery in the event of an outage.
To use clustered Data ONTAP with MetroCluster, NetApp highly recommends that you buy exactly four shelves to make the install and configuration cleaner. Each of those shelves is assigned to a node. So, for example, at Site 1, you could have Shelf 1 assigned to Controller A and Shelf 2 assigned to controller B. At the same site, Shelf 3 would be assigned to the secondary site Controller A, while Shelf 4 would be assigned to the secondary site Controller B. Those two pairs are their own HA cluster, giving customers a near-immediate failover option that can be on or off site.
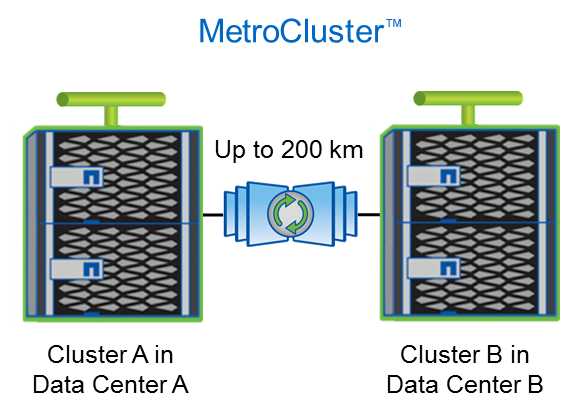
The downside of this is that your cost will naturally be higher because now you’ve got four nodes. Even if you don’t necessarily need the space of four shelves, you are committed to buying four. That could be a barrier to entry for a product that is already not cheap.
Cluster replication service
With MetroCluster, you have two separate clusters that are communicating over what they call a Continuous Replication Service, or CRS, which spans both sites. CRS keeps track of all the changes that happen on one site and then replicates those changes over to the other site. So if you create a storage virtual machine (SVM) at Site A, the CRS will then create a DR SVM at Site B.
This is all done on volume. As part of the initial MetroCluster setup, it creates those volumes as a sort of staging area. When you create an SVM, it writes it to this staging area volume. Then CRS copies that over to the other site’s CRS staging volume, applying all changes that need to be made. And because CRS goes over Ethernet, if an ISP were to fail then come back on, the CRS would pick up where it left off and write everything from that staging volume over to the other site.

New SMB3 features
If you’re running Hyper-V on SMB3, there is a cool new feature with 8.3 MetroCluster that allows you to move the interface over to another node and fail over controllers while maintaining uptime for your Hyper-V VMs. The only connections that will not be immediately available will be SMB3, which you would have to reconnect. With SMB3, the share locks don’t come over to the replicated site, which incurs some downtime in that event. NFS and SAN will have zero downtime if you do a site failover within two minutes.
MetroCluster Config Advisor
Formerly known as Wire Gauge, MetroCluster Config Advisor is new with 8.3. On standard, non-MetroCluster equipment, Config Advisor allows you to check wiring and firmware on your systems any time you want. Additionally, NetApp has included functionality for cDOT MetroClusters inside of Config Advisor. Before, if you had MetroCluster, this was not possible. Now, Config Advisor will work with MetroCluster to make sure everything is wired up correctly.
Simulated switchovers
In addition to “takeover” and “giveback” that was available in 7-Mode, MetroCluster on cDOT has added “switchover” and “switchback.” Before, with a 7-Mode MetroCluster, you could only do a takeover and giveback because there were only two nodes. Now, because MetroCluster operates in local HA, there is also switchover and switchback which switches the HA pair over to one site or the other. And whenever you make changes like creating an SVM, it creates those dormant SVMs on the other side. During a switchover, it’ll activate those dormant SVMs and run it in its own space. This allows you to quickly take over a whole site to operate and run tests.
Previously, if you had an unplanned switchover, there was a risk of your data getting out of sync. With 8.3, NetApp has added some commands to reduce this risk. Before you do your switchbacks, you can type a command like “metrocluster heal,” and that will determine what’s out of sync before you switch over. That command will either return an “L0” or “L1.” L0 means an entire set is out of sync, whereas L1 means only changed blocks need to be re-synced. This feature will make switchback a lot easier because MetroCluster will do most of the sync for you. That’s valuable time that adds up, particularly if you’re a large corporation with a lot of data sets.
Checks and balances with mirroring
With 7-Mode, you were allowed to have non-protected or non-mirrored aggregates. As a result, you might have two shelves on one site and one on another—and they would not necessarily match up. With MetroCluster in 8.3, before you create the MetroCluster, you have to mirror your aggregates. There’s an actual MetroCluster setup command that you have to do before it will allow you to run it. It goes and checks to make sure every single one of your aggregates are mirrored. While this doesn’t necessarily effect most customers, it could provide some extra protection for specific use cases.
MetroCluster in 8.3 will also run other pre-checks prior to doing a site switchover to make sure that data is locked down so that it doesn’t get out of sync. With cDOT, it’s easy to move data all the time, non-disruptively. To maintain that non-disruptive operations, MetroCluster will now alert you to data in flight before you do a switchover to make sure that you don’t incur any downtime.
Tiebreaker software
Within a MetroCluster, you have your Site A and Site B. You also have Site C, which is where the tiebreaker server is. It monitors both sites, so if Site A recognizes that Site B is down, and Site C (the tiebreaker software) also recognizes that Site B is down, the tiebreaker software will initiate a switchover automatically. With tiebreaker software enabled, your takeover time is no more than two minutes. While not everyone wants to do automatic failovers, this is a nice added feature.
What’s the impact to customers?
Right now, there is no upgrade path to cDOT MetroCluster, even if you are running ONTAP 8.3. It needs to be a net new install. Because MetroCluster utilizes ATTO bridges and not SAS cables, you’re going to have to undo the shelf connections to upgrade the equipment, which you can’t do without downtime. You’ll have to take the system down, re-cable everything, and then bring it back online. And the systems have to be the same across your MetroCluster nodes. Each cluster has to be the same type of storage system, whether they are FAS8020, 8040, 8080, etc.
All of the new features with MetroCluster in ONTAP 8.3 can greatly improve customers’ DR readiness, particularly when having data on-site or nearby is an important factor. While the cost for MetroCluster is still high, especially given the new 4-node constraints brought on by 8.3, the particular segment of the market that uses it will find these updates really helpful. With 8.3, ONTAP has delivered all of the functionality that MetroCluster had with 7-Mode in addition to plenty of enhancements that can dramatically improve performance and protection for customer data.
Now share this
[tweetable alt=”MetroCluster in #DataONTAP 8.3 can greatly improve #DisasterRecovery readiness #NTAPInsight @rnbeaty: http://zum.as/1ufaXe5″]MetroCluster in #DataONTAP 8.3 can greatly improve #DisasterRecovery readiness #NTAPInsight @rnbeaty[/tweetable]
[tweetable alt=”One of the most underrated technologies at #NTAPInsight? @rnbeaty says #MetroCluster – http://zum.as/1ufaXe5 #NetAppAdvocate”]One of the most underrated technologies at #NTAPInsight? @rnbeaty says #MetroCluster[/tweetable]